
Quelques sources : pour réaliser de ce billet de blog, je me suis entretenue avec Jean-Marie Bourgogne, délégué général d’Open data France, et avec Antoine Courmont, doctorant en sciences politiques travaillant au Grand Lyon sur le sujet « open data et gouvernance urbaine ». J’ai également lu le très bon livre de Simon Chignard Open data, comprendre l’ouverture des données publiques que je cite à de nombreuses reprises (voir aussi le blog de Simon Chignard).
Tout d’abord, qu’appelle-t-on « Open data » ?
L’open data, c’est littéralement la « donnée ouverte », c’est-à-dire la mise à disposition de données anonymisées, dans un format qui facilite leur réutilisation ultérieure et qui n’impose pas l’utilisation d’un logiciel propriétaire pour lire ces données. Pour prendre un exemple concret, la répartition de la population par âge et par département est une donnée. Une précision s’impose : l’open data s’intéresse donc aux données en tant que telles et à leur mise à disposition, et non pas à leur interprétation, c’est-à-dire au traitement de l’information que ces données contiennent.
Comme le rappelle Simon Chignard, le concept d’« open data » a d’abord vu le jour dans la communauté scientifique. Ainsi, le terme est utilisé pour la première fois en 1995 dans une publication d’une agence scientifique prônant la promotion de l’ouverture des données géophysiques et environnementales au vu de l’enjeu de bien commun qu’elles représentent.
D’ailleurs, Simon Chignard le souligne en introduction de son livre, l’un des tous premiers usages de données publiques relève du domaine scientifique, celui de la santé publique : au milieu du 19e siècle, le médecin anglais John Snow recense et cartographie les morts du choléra dans le quartier londonien de Soho. Cela lui permet ensuite d’établir que la contamination vient de l’eau de l’une des fontaines du quartier, et non de l’air vicié comme on le pensait à l’époque.
Si l’open data peut concerner a priori l’ouverture de tous types de données, y compris celles possédées par des associations ou des entreprises, on associe pourtant le plus souvent le terme au mouvement d’ouverture des données publiques, c’est-à-dire celles possédées par les administrations publiques.
Sous cette compréhension-là, l’open data est un mouvement d’origine anglo-saxonne soutenu et diffusé depuis le début des années 2000 par de nombreux intellectuels. Citons par exemple Tim O’Reilly, auteur et « père » du web 2.0. Sous son influence, l’administration de Barack Obama s’est d’ailleurs fait un premier grand promoteur de l’ouverture des données publiques. En réalité, l’open data s’inscrit même au sein d’un projet plus global de réinvention de l’action publique, l’open government, abrégé en Opengov et traduit par « démocratie ouverte » en français.
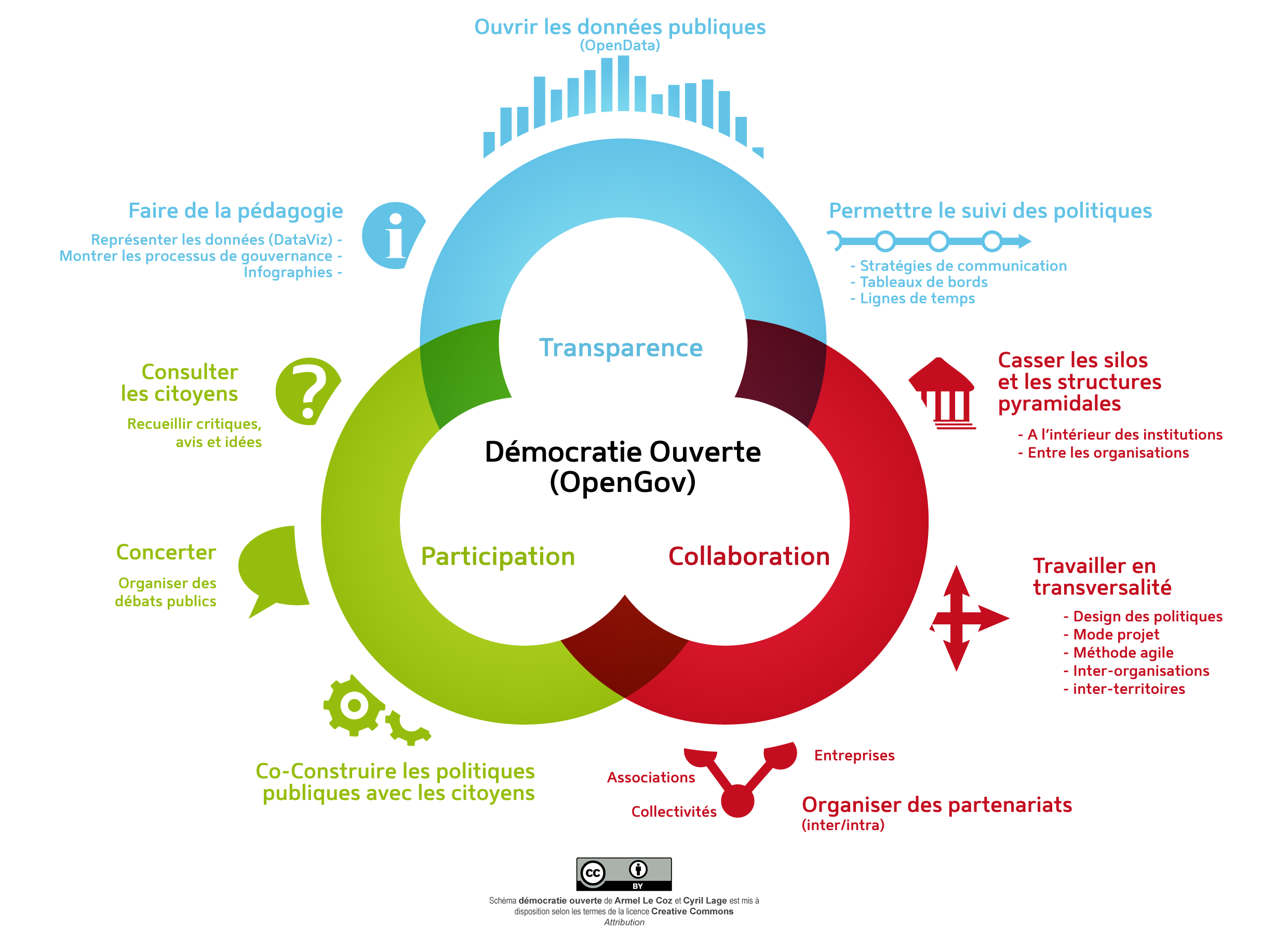
Schéma explicatif positionnant l’open data au sein de l’opengov
Source : Démocratie Ouverte
En France, les villes de Rennes, Montpellier, Bordeaux, Paris ou encore Toulouse ont fait parti des précurseurs du mouvement de l’ouverture des données publiques (voir le baromètre de l’open data de 2012). Principales données concernées par le mouvement Open data : les données territoriales quelles qu’elles soient (urbanisme et habitat, info géographiques, équipements et services…), les données liées à la mobilité, mais aussi les données liées à la santé. Bien entendu, la liste est non-exhaustive et d’autres types de données peuvent être concernées par l’open data – c’est le cas par exemple des données relatives à la culture.
Pourquoi ouvrir les données publiques ?
En général, deux objectifs principaux à l’ouverture des données publiques sont mis en avant :
- D’une part, rendre transparent l’accès du citoyen aux informations publiques et favoriser leur participation, dans l’idée de renouveler le lien entre l’administration et ses usagers. Par exemple, NosDeputes.fr, développé par l’association Regards Citoyens, permet de suivre l’activité des députés grâce à des données publiques. Autre exemple, l’expérience g0v.tw montée par Audrey Tang à Taïwan (voir le petit webdoc d’Arte consacré à Audrey Tang ou encore le g0v manifesto)
- D’autre part, favoriser l’innovation et permettre le développement de nouvelles entreprises en utilisant ces données publiques pour développer de nouveaux services. Par exemple, Géovélo, calculateur d’itinéraire à vélo, utilise des données publiques relatives au transport.
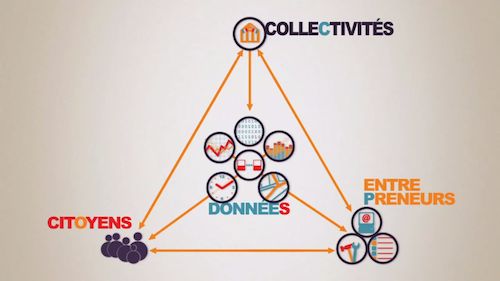
Un schéma racontant la vision classique de l’open data (source : youmood.me)
Mais au-delà de ce récit, Antoine Courmont relève un usage largement sous-estimé de l’ouverture des données publiques : leur usage par les administrations elles-mêmes, pour l’élaboration de nouveaux services publics ou leur amélioration. C’est également cet aspect qui est mis en avant dans un rapport intitulé Les données au service de la transformation de l’action publique publié en janvier 2016 par Henri Verdier, administrateur général des données (voir ci-dessous). En introduction du rapport, Henri Verdier détaille :
« […] négocier les achats d’électricité en anticipant en en contrôlant les pics de consommation ; mieux négocier les achats publics ; prédire les effets microéconomiques d’une réforme fiscale ; anticiper les besoins d’investissement médical grâce à l’analyse de la littérature scientifique… tous ces usages de l’analyse prédictive sont à portée de main de la puissance publique. Ils recèlent un immense potentiel d’efficacité, de maîtrise des dépenses et de justice de l’action publique. »
Comme toujours dans les concepts importés du monde anglo-saxon, l’idéologie politique sous-jacente au mouvement open source est difficile à catégoriser sur l’échiquier politique à la française. Ainsi, Simon Chignard explique-t-il :
« Peut-on classer l’idée politique d’open data à l’anglo-saxonne sur la grille de lecture gauche/droite qui prévaut en France ? Des premiers, l’idée d’open data reprend la notion de démocratie participative, de capacité du citoyen à participer à la décision collective, de bien commun, de décentralisation, d’esprit coopératif etc. De la droite libérale, l’open data retient surtout la volonté de ne pas laisser à l’État (sous toutes ses formes) le monopole des questions et des réponses publiques. On y retrouve aussi la croyance en la capacité du marché à assumer certaines fonctions de l’État. »
Les controverses
Bien entendu, le développement de ce mouvement a soulevé plusieurs controverses et questionnements. Sans chercher à les développer plus ici ou à prétendre à l’exhaustivité, en voici quelques uns :
- En quoi l’open data favorise-t-elle concrètement un renouveau du lien entre les administrations et leurs usagers ? En quoi la transparence favorise-t-elle la participation citoyenne de tous ? Ne favorise-t-elle pas au contraire la participation de certains seulement – à savoir ceux déjà en situation de domination ?
Exemple : Bhoomi est un programme indien lancé en 2001 et visant à l’ouverture de 20 millions de registres fonciers. Le chercheur Benjamin Solly a conduit une étude dans la région de Bangalore et a montré que ces données ont par exemple permis à de grands propriétaires d’évincer les occupants de certains terrains et ont éloigné les communautés de la gestion des sols (exemple issu du livre Open Data, comprendre l’ouverture des données publiques)
- Quel est l’effet de l’open data sur le tissu économique ? Favorise-t-il réellement la création d’entreprises, ou n’est-il pas au contraire plutôt utilisé en grande majorité par de grandes entreprises internationales comme Google, très actif dans le domaine des données de mobilités ?
Exemple : l’article de Jo Bates sur le site The Conversation raconte la libéralisation des données publiques météorologiques, leur usage par Monsanto et les risques potentiels que cela pourrait entraîner.
- Comment payer la production de données de qualité ? Est-ce justifié en termes de dépenses publiques face au bénéfice produit ? Faut-il penser un modèle freemium (une partie gratuite, une partie payante) ?
Exemple : depuis des années, l’IGN a construit son modèle économique sur la vente de certaines de ses données. L’injonction à l’ouverture des données de l’IGN pose donc une vraie question pour son évolution – changer son offre de service. Cela oblige notamment l’institut à se positionner sur une offre de conseil.
- Les données sont-elles réellement anonymes ? Les données personnelles sont-elles réellement protégées ? L’ouverture de toujours plus de données de santé ne présente-t-elle pas un risque pour la protection des données personnelles ?
Exemple : En France, une frontière assez stricte a été marquée entre les données accessibles et les données à caractère personnel. Cependant, Simon Chignard relève que cette distinction n’est pas aussi stricte dans le monde anglo-saxon. Ainsi, à Chicago, la liste de tous les employés municipaux ainsi que leurs rémunérations est le fichier le plus populaire du site d’open data de la ville. De même, Antoine Coumont évoque des exemples où les fichiers anonymes ont pu être « désanonymisés » grâce au croisement de plusieurs jeux de données.
Au-delà de ces controverses, le sujet soulève bien sûr de nombreuses questions d’ordre technique : comment créer des normes pour que les données produites par les différents services/administrations soient comparables entre elles ? Comment assurer l’actualisation des données ? Comment améliorer l’interopérabilité des fichiers des différentes administrations ? Faut-il mettre les données en téléchargement ou accessible via application dédiée – aussi appelée API ? Faut-il choisir un format ouvert de type CSV, ou bien un format standard de type Excel ? Quelle licence utiliser pour protéger les données ?…
Qui sont les acteurs de l’open data aujourd’hui ?
Deux acteurs institutionnels principaux
Etalab, mission créée en 2011, intégrée au Secrétariat général pour la modernisation de l’action publique et placée sous l’autorité du premier ministre, est chargée de mettre en application la politique d’ouverture et de partage des données publiques en France. Etalab gère notamment le site http://www.data.gouv.fr/ et accompagne les ministères et grandes organisations publiques dans la démarche d’ouverture des données. Etalab assure un travail auprès des parlementaires pour faire évoluer la législation relative à l’open data et essaye de stimuler la réutilisation des données publiques en organisant par exemple des hackathons. Preuve que les données sont devenues un enjeu à part entière pour les administrations, Henri Verdier, directeur d’Etablab, est nommé administrateur général des données (chief data officer) en 2014, un poste inédit en France jusque-là.
Côté collectivités, Open data France se positionne comme la tête de réseau des initiatives open data. Créée il y a trois ans (même si la structure, elle, n’existe que depuis deux ans), les missions de cette association sont de permettre aux collectivités de se regrouper, de s’entraider et bien sûr de promouvoir une vision commune autour de l’open data. L’association représente aujourd’hui une soixantaine d’adhérents et possède un salarié, son délégué général Jean-Marie Bourgogne.
Chez les acteurs de la société civile, des visions contrastées de l’open data…
LiberTIC et Regards Citoyens sont deux associations, toutes deux créées en 2009 et dont l’objet est la promotion de l’open data en France. Dans son ouvrage, Simon Chignard qualifie leur vision de « participative » : pour que l’open data ait un sens, il faut que d’autres acteurs, à tous les niveaux, y participent activement. De même, la FING se positionne bien sûr sur la question. Ainsi, en 2009, le think-tank publie-t-il avec le cabinet d’étude Chronos La Ville 2.0, plateforme d’innovation ouverte. Au-delà de l’open data, la FING travaille sur l’appropriation des données au sens large, notamment via les infolabs.
A l’opposée de cette vision participative, l’iFRAP a publié en 2011 un manifeste intitulé « Les données nous appartiennent ! » reposant sur une idéologie plus libérale instituant une défiance envers les institutions publiques.
Les chercheurs et l’open data
Le chercheur star sur la sociologie des algorithmes est bien sûr Dominique Cardon, auteur notamment de La démocratie internet. Promesses et limites en 2010, ou encore de À quoi rêvent les algorithmes. Nos vies à l’heure des Big Data en 2015. En sociologie de la quantification, l’auteur de référence est Alain Desrosières qui a notamment publié en 2014 Prouver et gouverner : Une analyse politique des statistiques publiques.
Toutefois, le domaine spécifique de l’ouverture des données publiques est encore balbutiant en France. On y trouve quelques laboratoires techniques travaillant sur des aspects assez techniques. C’est le cas par exemple du LIRIS de l’INSA Lyon ou du master Big data de Telecom ParisTech. L’Open data intéresse également les juristes, dont par exemple Benjamin Jean qui a fondé le cabinet innocube.
Enfin, plusieurs jeunes chercheurs/doctorants plutôt politistes ou sociologues travaillent actuellement sur le sujet. En voici trois, sans prétendre à l’exhaustivité :
- Catherine Dewailly est en thèse chez Opendata France. Son sujet de thèse porte sur les enjeux et les perspectives de l’ouverture des données publiques
- Antoine Courmont, que nous avons déjà cité ici, est en cours de thèse à Science Po et au Grand Lyon. Il travaille sur le thème « Open data et urban governance »
- Enfin, Samuel Goëta fait une thèse au sein de Telecom Paristech. Son sujet : Open data, behind the scenes: sociology of production and liberation of government data. Il est très impliqué dans le projet d’École de la donnée, version française de la School of Data lancée par l’Open Knowledge Foundation.
Et d’un point d’un point de vue législatif ?
En France, le texte de référence concernant l’open data est la Cada de 1978 modifiée par la directive européenne 2003/98/CE de 2005. Toutefois, des lois récentes viennent dépoussiérer un peu ce corpus réglementaire.
Ainsi, à l’été 2015, la loi NOTRe impose l’accès libre à certaines données territoriales à pour les collectivités locales. Toutefois, la question de la réutilisation des données n’est pas tranchées dans ce texte et renvoie aux textes antérieures (càd à la loi Cada)
Enfin, la très récente la loi Lemaire prévoit l’ouverture de quatre type de données, essayant d’instaurer un service public de la donnée et un open data « par défaut » – même si ce principe est mis en doute par certains acteurs de l’open data :
- Les bases de données (et leur contenu)
- Les documents communiqués à des particuliers suite à des procédures « CADA », ainsi que leurs « mises à jour »
- Les « données dont l’administration, qui les détient, estime que leur publication présente un intérêt économique, social ou environnemental »
- Les « principaux documents » figurant dans le répertoire d’informations publiques prévu par l’article 17 de la loi CADA
Pour aller plus loin : Opendata France propose un document synthétisant tous les textes de loi relatifs à l’opendata.
L’open data, et après ?
On l’a vu, l’open data est mouvement encore jeune en France. Il monte en puissance tout en se structurant petit à petit autour d’un réseau d’acteurs de références. Pourtant, au-delà de l’open data seule, des questions plus larges se posent déjà. En effet, la question de l’ouverture des données publiques ne sera-t-elle pas bientôt supplée par la question de données personnelles et du traitement de cette gigantesque masse de données (le « big data ») ? La transparence et le contrôle des citoyens proposée en vision par l’open data n’est-elle pas un pas insuffisant vers une relation entre citoyen et action publique renouvelée et coopérative ?…



{kind=link}